Lessons from the first broad testing #1
Last week we introduced the Calibur pocket box. It is once again a major leap in product design and features. Testing it is the last step before actual production.
The plan is something like this:
1.Build a very reliable, stable and accurate device
2. Use that basis to build on all the smart features in the application.
We ran a broad épée test back in November which served as a way to pinpoint the weaknesses, analyze the data and incorporate it into a new device. It’s worth summarizing the major takeaways. Today we’ll cover technical issues and how we addressed them:
Connectivity
Let’s jump start to connectivity. Connectivity is the bread and butter of a wireless system. You can only make wireless as good as the quality of connection is. It is judged by 2 factors: stability and latency. To put it more simply how often the connection drops and how much time it takes for a hit to display. The boxes we shipped in November had inconsistencies in both fields, so we put a lot of effort in fixing it.
Stability:
In general Apple devices disconnected much sooner than the ones with Android, but we were able to improve on both systems. The development is pretty obvious on this part, we were able to drive down drops to practically 0. Tested on a dozen different, low-end to high-end phones and tablets connection always remained active. The challenge is now to find an otherwise well-functioning phone that fails this test and I’m happy to tell that we haven't find one.
Latency:
The latency is a bit more complex issue. How long is good enough actually? We found that the threshold for unnoticeable delay to be around 100ms.
The results are again very promising. The delay dropped significantly and stayed low up until around 15 meters. So now it is up to the phone to process it.
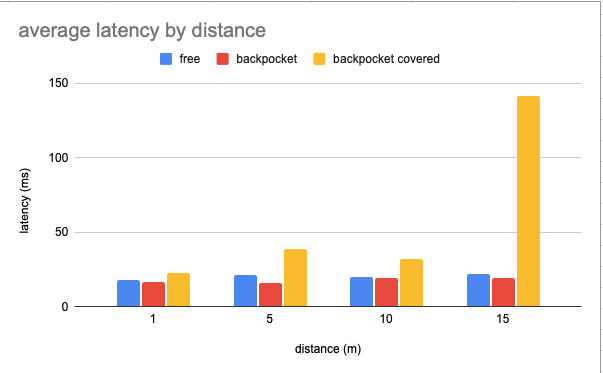
Getting the phone's processing time down proved to be harder to optimise than anticipated. But it’s clear that the delay is mainly caused by the application now which will perform much better after restructuring. More on that later.
Accuracy
The idea that accuracy is based on the utilization of the data pool is a sort of chicken-egg problem. To have people using the devices they need to be enjoyable. To be enjoyable people need to use it. So the deal with the broad épée test was that people would be using them even when it’s not so enjoyable and we will quickly follow-on with updates and by the end of the test they will become quasi-replacement for any system on épée.
After a very strong start, restrictions started to kick in in December basically everywhere and the incoming data started to slow down. But we still managed to get thousands of bouts and tens of thousands of touch data. Huge thanks to our testers for keeping up despite all the hurdles! Two things became clear: 1. That the data will be not sufficiently big with the current model (it's not just a matter of the total volume but the constant flow, to make comparison after every version) and 2. that we certainly underestimated how much work it will be to maintain a system and to develop a new one parallel. So we moved forward and put the focus on incorporating the existing data into the next version.
The goal was to make accuracy high enough so that fencers will enjoy using the devices in training sessions and the rest of the data will come much easier. The 2 major questions in accuracy are: does it go off when it shouldn’t and do we need calibration to avoid that? We were able to improve tremendously on both aspects.
TLDR: The general direction is very clear latency is down, accuracy is up. We are getting through the 3rd wave (so far) of the pandemic and with local clubs shut down, it's more tricky to find the ways for sufficient testing. In our testing the system works well in 90-95% of the cases. So the job for the AI is to close the remaining gap particularly on rare cases. Global testing will start next month with the goal of finding the outlier cases. As soon as the data feed start to improve again so will the system.
In the next posts we will cover the general feedback and future features but for ending watch this video of a short bouting in the office.